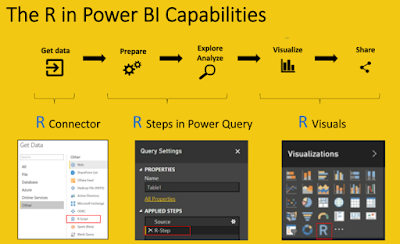
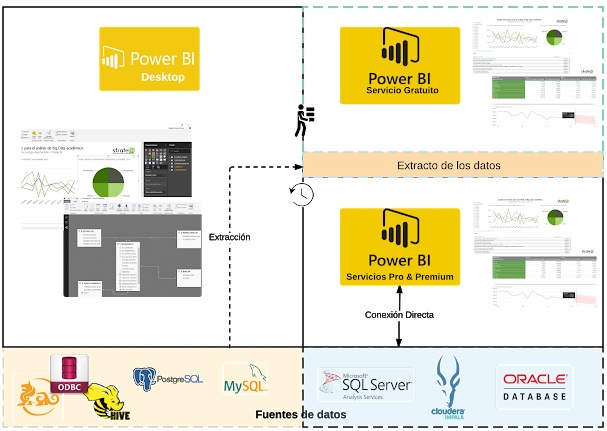
Hace unos días os contábamos que Google ya había dejado disponible Data Studio, saliendo del beta. Ahora os contamos primeras impresiones.
Lo primero: no es un ETL tipo Pentaho Data Integration o Talend, se trata más bien de una herramienta 'data preparation', muy útil para el ecosistema Google, pero que aun debe madurar bastanteIntroducción
Google Data Studio se basa en tres principios: conexión con una fuente de datos, generación de informes y distribución.
Conexión
Google permite una gran cantidad de conexiones a diversas fuentes de datos. Los distintos conectores están divididos en tres secciones:
- Google Connectors: desarrollados por google.
- Partner Connectors: desarrollados por los partner Data Studio.
- Open Source Connectors: desarrollados por la comunidad.
Por parte de google se permiten conectores tradicionales JDBC a bbdd relacionales (PostgreSQL, MySQL). Adicionalmente, permite la conexión contadas las herramientas de Google Cloud y una gran cantidad de APIs provenientes de sus Partners.
Informes
Antes de generar informes Data Studio permite realizar cierto tratamiento de datos:
En este punto se observa que, la herramienta necesita de más desarrollo debido a:
Tras seleccionar los campos del datasource se puede proceder a la creación de informe:
La interfaz recuerda a PowerBI, sin tener la mitad de las funcionalidades disponibles en el mismo. Aunque, existe cierto potencial en la capacidad para cruzar fuentes de datos distintas desde la opción COMBINAR DATOS, pero conlleva una correcta estructuración previa de los datos (que habrá que realizar con otra herramienta: PDI/Talend).
Se ha realizado una pequeña Demo utilizando los servicios disponibles desde la API de Star Wars:
En la demo se ha podido observar que carece de la posibilidad de moverse entre las dimensiones, es decir, no se puede hacer drill en las gráficas solo disponemos de los filtros definidos por el usuario.
Distribución
Uno de los puntos positivos encontrados es que permite compartir la edición con otros usuarios de google y trabajar en el mismo informe en paralelo. Para ello simplemente es necesario generar un enlace con permisos de edición.
Conclusión
En conclusión, Google Data Studio es una herramienta en proceso de ser terminada, la funcionalidad actual es tener la capacidad de crear informes con datos de prueba suministrados por APIs o Datasources previamente estructurados.
Por lo tanto, no se puede comparar a una herramienta ETL como Talend o PDI, más bien, se podría comparar a STDasboard/PowerBI, etc... que permite la generación de Dashboards/Informes sin que el usuario tenga que depender de conocimientos previos.

 Como construir diversos tipos de mapas (incluye código)
Como construir diversos tipos de mapas (incluye código)