Sin embargo, cuando trabajamos con fuentes de datos con características de Big Data (Volumen, Variedad y Velocidad), nuestras tablas de métricas (por ejemplo, volumen de ventas, unidades...) y aquellas tablas que describen el contexto (por ejemplo, fecha, cliente, producto) podrían almacenar miles de millones de filas, lo que hace que los requisitos de procesamiento sean muy elevados, incluso para las tecnologías Big Data más avanzadas.
Por ello, se ha creado este estudio muy completo que, por primera vez, y de forma rigurosa, compara el rendimiento de las diferentes alternativas para realizar Big Data Analytics

**Download free 27 pages whitepaper ''Big Data Analytics benchmark'
**Download free 27 pages whitepaper ''Big Data Analytics benchmark'
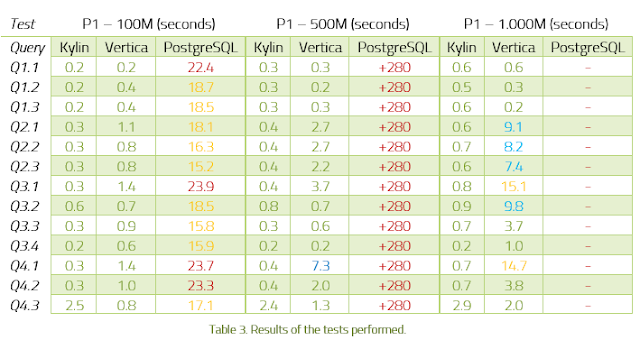
Para soportar las aplicaciones OLAP con Big Data, en los últimos años han surgido múltiples tecnologías que prometen excelentes resultados. Algunas de los más conocidos son Apache Kylin, Vertica, Druid, Google Big Query o Amazon Red Shift.

En este whitepaper describimos las tecnologías Big Data OLAP que forman parte del benchmark: Apache Kylin y Vertica.

Además de comparar estas tecnologías entre sí, también las hemos comparado con la base de datos relacional PostgreSQL.
Esta tecnología de código abierto, a pesar de no ser una base de datos Big Data, suele ofrecer muy buenos resultados para los sistemas OLAP tradicionales. Por lo tanto, consideramos que valía la pena incluir PostgreSQL para medir sus diferencias con Kylin y Vertica en un escenario de Big Data OLAP.
LinceBI, solución analítica basada en código abierto, utiliza estas tecnologías para un rendimiento escalable y más rápido en Business Intelligence
More Info:
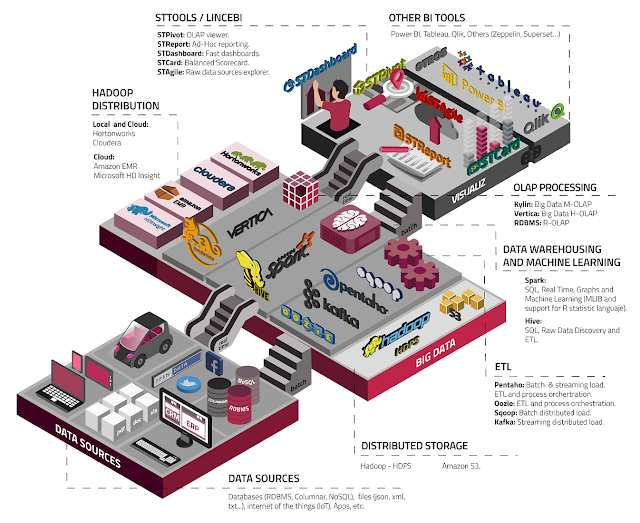
OLAP for Big Data. It´s possible?
Hadoop is a great platform for storing a lot of data, but running OLAP is usually done on smaller datasets in legacy and traditional proprietary platforms. OLAP workloads are beginning to migrate to the one data lake that is running Hadoop and Spark. Fortunately, there are a number of Apache projects that are starting to make OLAP possible on Hadoop. Apache Kylin For an introduction to this interesting Hadoop project, check...