Os venimos contando desde hace ya un tiempo, el potencial del mundo Big Data y OLAP Business Intelligence, con diferentes tecnologías. Hoy, os contamos la arquitectura usando Superset, creado por AirBnB
Nuestros compañeros de Stratebi han creado un entorno de prueba para que lo veas, además, en funcionamiento
Información publicada recientemente sobre el tema:
- x50 faster 'near real time' Big Data OLAP Analytics Architecture- Comparacion de sistemas Open Source OLAP para Big Data
- Use Case “Dashboard with Kylin (OLAP Hadoop) & Power BI”
- Cuadros de mando con Tableau y Apache Kylin (OLAP con Big Data)
- BI meet Big Data, a Happy Story
- 7 Ejemplos y Aplicaciones practicas de Big Data
- Analysis Big Data OLAP sobre Hadoop con Apache Kylin
- Real Time Analytics, concepts and tools
- Hadoop Hive y Pentaho: Business Intelligence con Big Data (Caso Practico)
Arquitectura:
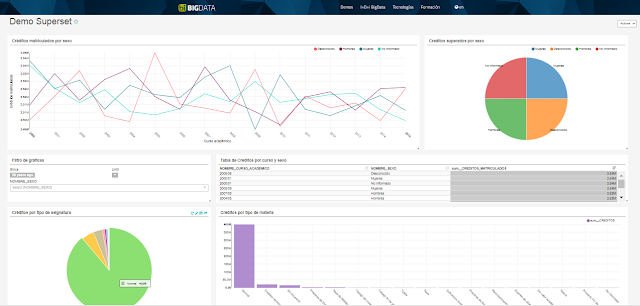
En el caso de estudio que presentamos, hacemos uso de las herramientas Apache Kylin y Apache Superset para dar soporte al análisis mediante Cuadros de Mando de un almacén de datos (Data Warehouse, DW) que contiene datos con características Big Data (Volumen, Velocidad y Variedad). Se trata de un gran Volumen de datos académicos, relativos a los últimos 15 años de una universidad de gran tamaño. A partir de esta fuente de datos, se ha diseñado un modelo multidimensional para el análisis del rendimiento académico. En él contamos con unos 100 millones de medidas cómo los créditos relativos a asignaturas aprobadas, suspendidas o matriculadas. Estos hechos se analizan en base a distintas dimensiones o contextos de análisis, como el Sexo, la Calificación o el Año Académico.
Dado que este Volumen de datos es demasiado grande para analizarlo con un rendimiento aceptable con los sistemas OLAP (R-OLAP y M-OLAP) tradicionales, hemos decidido probar la tecnología Apache Kylin, la cual promete tiempos de respuesta de unos pocos segundos para Volúmenes que pueden superar los 10 billones de filas en la tabla de hechos o medidas. Además, para hacer posible la exploración de los datos del cubo de Kylin mediante lenguaje SQL y la creación de cuadros de mando que podamos compartir con los usuarios finales de los datos, hemos hecho uso de la herramienta Superset. Apache Superset es una herramienta de visualización desarrollada por AirBnb de reciente creación. Facilita la creación de cuadros de mando de forma intuitiva y destaca por ofrecer una gran variedad de representaciones gráficas tanto para la exploración como para la visualización de los datos.
La herramienta Superset incluye de serie conectores para Sqlite y Druid pero dispone de una serie de paquetes para realizar conexiones con otras fuentes de datos. El uso del estándar SQLAlchemy permite realizar consultas en diferentes orígenes de datos, siempre que se disponga del conector correspondiente. Mediante el uso del conector con Kylin (kylinpy), es posible enviar consultas a Kylin utilizando SQL.
Superset incluye un entorno de consultas (SQL Lab) que permite desarrollar consultas SQL sobre una fuente de datos para dar soporte a una representación gráfica. Por otra parte, Superset permite crear cuadros de mandos a partir de las gráficas generadas (que parten de las consultas SQL realizadas). Tras crear el cuadro de mandos, es necesario gestionar los permisos para conceder acceso al mismo a los usuarios autorizados. En este caso se ha configurado Superset para permitir el acceso público a este cuadro de mandos.
Desarrollada por eBay y posteriormente liberada como proyecto Apache open source, Kylin es una herramienta de código libre que da soporte al procesamiento analítico en línea (OLAP) de grandes volúmenes de datos con las características del Big Data (Volumen, Velocidad y Variedad). Sin embargo, hasta la llegada de Kylin, la tecnología OLAPestaba limitada a las bases de datos relacionales o, en el mejor de los casos, con optimizaciones para el almacenamiento multidimensional, tecnologías con importantes limitaciones para enfrentarse al Big Data. Apache Kylin, construida sobre la base de distintas tecnologías del entorno Hadoop, proporciona una interfaz SQL que permite la realización de consultas para el análisis multidimensional de un conjunto de datos, logrando unos tiempos de consulta muy bajos (segundos) para hechos de estudio que pueden llegar hasta los 10 billones de filas o más. Las tecnologías del entorno Hadoop fundamentales para Kylin son Apache Hive y Apache HBase. El almacén de datos (Data Warehouse, DW) se crea en forma de modelo estrella y se mantiene en Apache Hive. A partir de este modelo y mediante la definición de un modelo de metadatos del cubo OLAP, Apache Kylin, mediante un proceso offline, crea un cubo multidimensional (MOLAP) en HBase. Se trata de una estructura optimizada para su consulta a través de la interfaz SQL proporcionada por Kylin. De esta forma cuando Kylin recibe una consulta SQL, debe decidir si puede responderla con el cubo MOLAP en HBase (en milisegundos o segundos), o sí por el contrario, no se ha incluido en el cubo MOLAP, y se ha ejecutar una consulta frente al esquema estrella en Apache Hive (minutos), lo cual es poco frecuente.
Por último, gracias al uso de SQL y la disponibilidad de drivers J/ODBC podemos conectar con herramientas de Business Intelligence como Tableau, Apache Zeppelin o incluso motores de consultas MDX como Pentaho Mondrian, permitiendo el análisis multidimensional en sus formas habituales: vistas o tablas multidimensionales, cuadros de mando o informes.
Superset es una herramienta de visualización de código abierto desarrollada por AirBnb y liberada como proyecto Apache. Se trata de un proyecto de reciente creación que se encuentra en proceso de desarrollo. Esta herramienta destaca por disponer de un amplio abanico de representaciones para la exploración y visualización de datos, posibilitando la creación de cuadros de mando así como por su sencillez de uso y alta disponibilidad, siendo diseñado para funcionar bien tanto en ordenadores personales como en entornos distribuidos.
Por otra parte, Superset utiliza SQLAlchemy para facilitar la integración con diferentes gestores de bases de datos relacionales (como MySQL, PostgreSQL, Oracle, etc.) así como otros gestores de datos no relacionales orientados al Big Data (como Kylin, Druid o Vertica). Para realizar la conexión de Superset con alguna de estas fuentes de datos, se necesita instalar un paquete que actúa como middleware y configurar la conexión con SQLAlchemy.
Otras funcionalidades por destacar de Superset son la seguridad y autenticación que permite el uso de fuentes como LDAP, OAuth o OpenID. Se pueden utilizar diferentes usuarios y roles con permisos específicos de acceso, creación o modificación de fuentes de datos, gráficas, cuadros de mando etc.
Sí estas interesado en hacer tu proyecto con esta tecnología no dudes en solicitar presupuesto en StrateBI.